How Ripple uses Fibers
by Sean Cribbs
Fibers, really? Yes, really. Ripple (riak-client, actually) has used fibers even since 0.6, almost exactly a year ago (I probably got the idea from Dave Thomas). In the most recent few commits, I finally extracted and generalized how they are being used as I am finding more and more uses for the pattern, which I'm calling a “Pump” (short for message pump).
I was asked by Evan Phoenix on Twitter (and retweeted by others) how the code was useful, and I tried to explain in a series of tweets back and forth, but failed to get my point across. Surprise, concurrent code is hard to explain on Twitter! This blog post should help explain.
Note that I use Curl/curb as an example below, but the problem occurs in other clients (e.g. Excon) as well.
Simple requests
Before we can understand why this problem occurs, let's look at the simple case, which is the single-threaded call-and-return pattern.
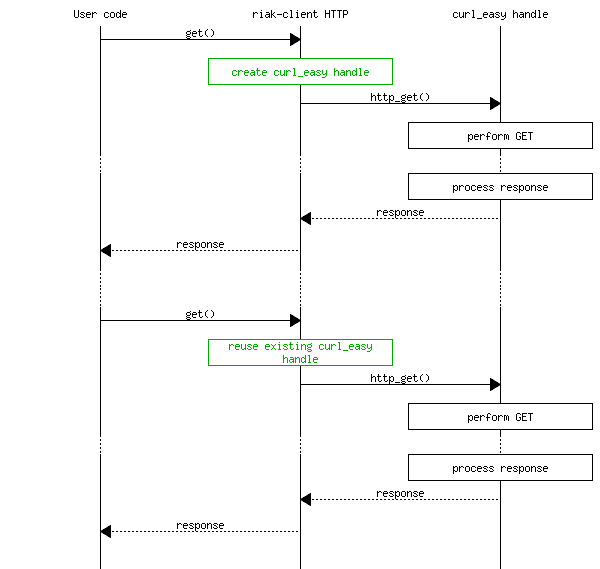
This is really simple to understand. We make a request, calls go down several layers until they hit the Curl C library, and then responses bubble back up to the user code. For efficiency's sake and the added benefit of keeping existing connections open, we reuse the curl_easy handle when starting a new request.
With that out of the way, let's get to the interesting stuff.
Streaming
Riak's HTTP API
supports a number of streaming operations, including key lists,
MapReduce, and large files (Luwak). How are streaming operations
different than regular HTTP responses? If you're at all familiar
with HTTP, you may have heard of “chunked-encoding”.
Instead of returning a Content-Length header in the
response, the HTTP server sends a header of Transfer-Encoding:
chunked, and then sends length-prefixed “chunks” of
the response body. This lets the server send dynamic content, or
buffer the response in smaller pieces so as to limit resource
consumption. You can read more about how it works on
Wikipedia.
Now why is chunked encoding interesting to us? It means on the client you can choose to do something as each chunk arrives. That is, while the response is still being processed and the socket is still in use, you can do something with the intermediate result. Keep the bolded bit in mind when reading what happens below.
The natural way to implement that “do something when a chunk comes in” pattern is to pass a block, so that's what Ripple does, like in the sample code below.
bucket = Riak::Client.new['foo']
bucket.keys do |keys| # Request happening here
keys.each {|k| bucket.delete(k) } # Another request happening here
endHere's where the fun (and confusion) starts.
Ripple before Fibers
Lots of code has changed in Ripple's Curb adapter since 0.5, but I think it should be clear enough what happened in that version. Basically, the block the user passed to the HTTP client wrapper gets passed nearly directly to the Curl library as the “on_body callback”. We wrap the user's block with our own so we can meet the required protocol of returning the read chunk size to curl.
This is all well and good until you want to make another request from inside the block that is receiving data. Remember how we kept the Curl handle around for reuse between requests? Here's where our code blows chunks (pardon the pun).
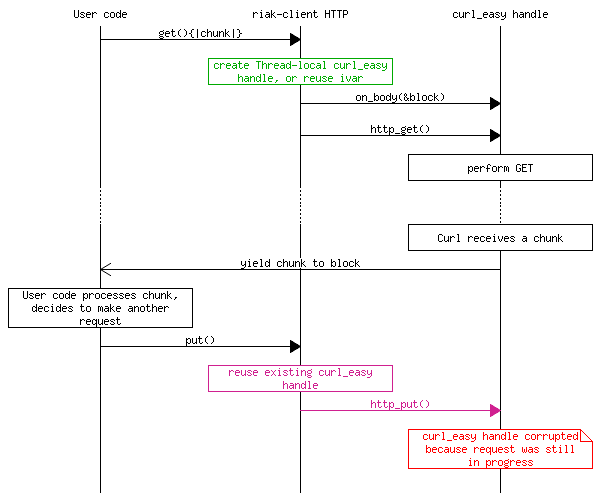
When we've re-entered the client wrapper, we need to protect that Curl handle from being reused until the original response has finished. On the other hand, we DO want to reuse the handle after the whole cycle is done. If you're getting the sense that we're dealing with an issue of concurrency here, you're right; and yet there's no Threads in sight!
The rub is that Curl passes control to the on_body
callback as soon as data is available. Since Ruby doesn't know that
anything has changed, that callback runs in the same Thread as the
original request, so even Thread-local variables won't protect
against handle corruption.
Enter Fibers
Naturally, it seems like we should wrap the callback in its own Thread, but then we need to do some serious flow-control to avoid deadlocks and race-conditions. Personally, I don't like dealing with semaphores and critical sections, it's just too fiddly (maybe a reason I'm drawn to Erlang, although that doesn't necessarily solve the problem). Luckily, Fibers can help. We can make the code appear and behave as if there were only one Thread, but also isolate the callback inside its own context. Don't believe me? Witness the code below (run in IRB originally):
# Fibers get their own Thread locals
Thread.current[:foo] = 1
# => 1
f = Fiber.new do
p Thread.current[:foo]
Thread.current[:foo] = 2
p Thread.current[:foo]
end
# => #<Fiber:0x00000101470598>
f.resume
# nil
# 2
# => 2
Thread.current[:foo]
# => 1 The best way I found to understand Fibers is to either liken them to UNIX pipes, or to look at the implementation of them for Ruby 1.8 that Aman Gupta wrote (and is included for compatibility's sake in Ripple).
In Aman's implementation, a Fiber is a Thread that has two Queues
attached, an incoming (resume) queue and an outgoing (yield)
queue. Since the pop operation on a Queue blocks until
there is something to pop, you can pass control to the internal
Thread by calling resume, which will then block on the
outgoing queue for a result. When the internal Thread finishes its
work, it calls yield, which will push a value
(potentially nil) onto the outgoing queue and return control to the
Thread that originally called resume. Wow, what a mouthful!
The moral of the story is that Fibers only execute when you
call resume and return control to the resumer when they
call yield.
The Pump
Finally we get to the “pattern” I decided to call
the Pump in Ripple. Pump or message pump is really
another name for a miniature event
loop. You might have heard of that idea
before.
Fiber.new do
loop do
block.call Fiber.yield
end
endFiber.yield sits around waiting for input and when it
gets it, calls the block with the passed value. When the block
returns, we begin the whole cycle all over again. Now all the HTTP
code has to do is resume the fiber when it receives a chunk (the
actual code is slightly different, but this is the gist of it):
def to_proc
lambda {|chunk| fiber.resume chunk }
endBecause a picture is worth a thousand words, and describing this will get hairy pretty quickly, I'll let the picture do the talking.
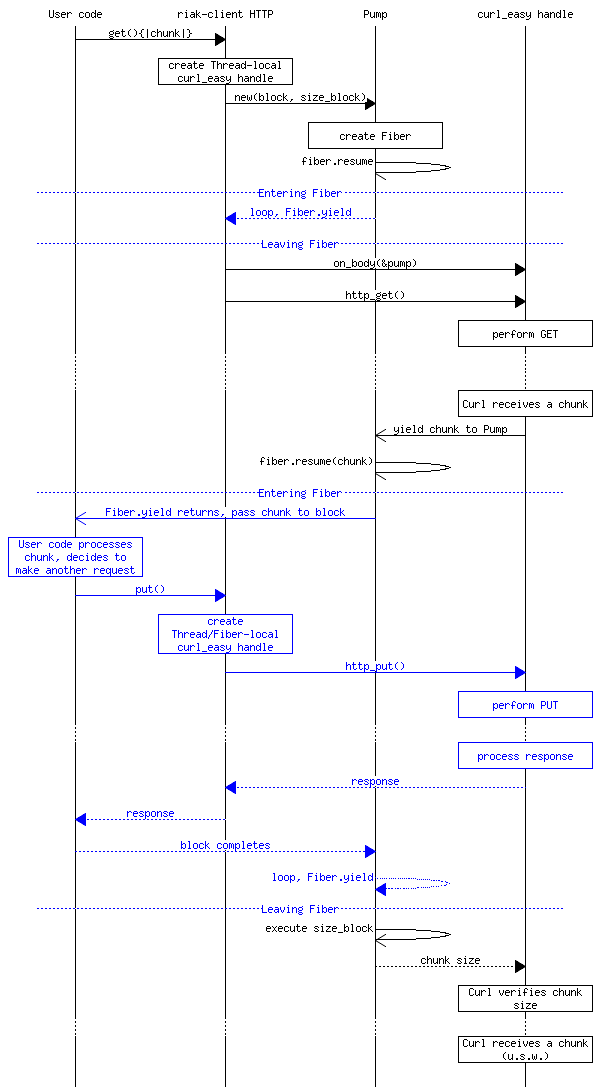
If you want to see the actual code that the diagram is based on, check it out on Github. It might also be instructive to see how the Pump is used inside the client wrappers (Curb, Excon).
Other options
There's more than one way to skin a cat, or to solve most technical problems. Some will say I should have made a connection/thread pool. They're probably right. This works for me, is a lightweight solution with small system impact, and I'm finding it useful as I implement other parts of the client (the Protocol Buffers interface, for instance).
Cheers!