GRE Preparation: Ruby to the Rescue
by Sean Cribbs
My wife is preparing to take the GRE General Test which includes three essay questions. She asked me to help her by selecting questions at random from the pool of available questions so she could practice them. There are two “issue” questions and one “argument” question on the test. I looked at the question pools and thought, “Ugh. How am I going to do this?” Luckily, I had just finished a few hours of work this morning for Digital Pulp and was in a Ruby mood. Here’s what I came up with to ease the pain.
Collecting the questions
First, I had to determine how to pull the questions out of the page on ETS’ website. So I whipped out Firebug’s inspector and clicked on one of the questions.
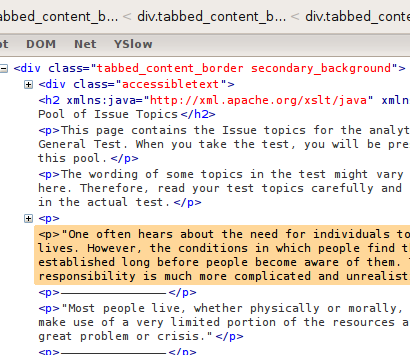
From the image, you can see that they are organized in paragraphs under this div with two classes. However, we don’t want all the paragraphs as some of them are irrelevant or ill attempts at creating a border between questions. The ones that begin and end with quotation marks are relevant.
So let’s write some code! I made a QuestionParser class that began like this. First, we need to download the page:
require 'open-uri'
class QuestionParser
attr_accessor :url
def initialize(url)
self.url = url
end
def content
@content ||= open(url)
end
endSo now that we have the source downloaded, let’s parse it with Hpricot. (The require lines will go at the top and the method inside the class.) By looking through the source, I’m pretty sure there’s only one div with the class “secondary_background”, so we’ll use that in our selector.
require 'rubygems'
require 'hpricot'
def paragraphs
doc = Hpricot(content)
doc / "div.secondary_background p"
endNow we have all the paragraphs in that div, but we really only want the ones in quotes, so let’s filter them out. In this case, I’m going to add the ActiveSupport gem for extra Symbol.to_proc goodness.
require 'active_support'
def questions
paragraphs.map(&:inner_text).select { |p| p =~ /^"[^"]+"/ }
endSo now that we have all the questions, what are we going to do with them? Let’s save them to a file, but with one twist. I want to be able to track which questions have been taken so she doesn’t do the same one twice. So we’re going to store the questions as a YAML-serialized hash, with two keys, ‘new’ and ‘used’. We will store taken questions under the ‘used’ key. But since we’re just generating the files for the first time, they can all be stored in the ‘new’ key.
require 'yaml'
def save_file(filename="questions.yml")
data = {'new' => questions}
File.open(filename, "w") { |f| YAML.dump(data, f) }
endThen, at the end of the file, outside the class, we can download, parse, and save out our questions in two lines (one for the issues page, one for the arguments page). I’ve removed the URLs because they’re obscenely long:
QuestionsParser.new(ISSUES_URL).save_file("issues.yml")
QuestionsParser.new(ARGUMENTS_URL).save_file("arguments.yml")Selecting questions
Now that we have downloaded, parsed, and saved our questions, let’s create a process to select them randomly. Let’s start with some boilerplate. We need to load the issues and arguments from their YAML files, and also have some way to store the selected questions.
require 'yaml'
class QuestionSelector
attr_accessor :issues, :arguments, :current_questions
def initialize
self.issues = YAML.load_file('issues.yml')
self.arguments = YAML.load_file('arguments.yml')
self.current_questions = []
end
endNow, let’s create a method to select a random question from one of the loaded YAML data. Once a question is selected, we want to add it to the current questions, and put it in the ‘used’ hash key for its collection so it doesn’t get selected again. Since I intend to print these later on, I want to be able to tell whether it’s an issue type or an argument type question, so we’ll prepend some text that identifies it.
def select_question(hash, prefix)
question = hash['new'].delete( hash['new'].sort_by { rand }.first )
hash['used'] ||= []
hash['used'] << question
current_questions << [prefix, question].join(" : ")
endThat code deserves a bit of explaining. First, we’re going to delete the question from the ‘new’ collection. Which question is selected is determined by sorting the collection randomly and then picking the first one. Then, we lazily initialize the ‘used’ collection to an empty array and push the question into the collection. Finally, we add it to the current_questions with its prefix separated by a colon and two spaces.
Now, in each test, as mentioned above, there are two issue questions and one argument question. So let’s select those.
def select_round
2.times { select_question(issues, "ISSUE") }
select_question(arguments, "ARGUMENT")
endNow that we can select questions for a full test, let’s do something with them… namely, print them! After we’re done, let’s save the modified data back to the YAML files and clean things up.
def take_questions
select_round
current_questions.each do |q|
File.open("question.txt", "w") {|f| f.write q }
system "lpr question.txt"
end
save_files
end
def save_files
File.open("issues.yml", "w") {|f| YAML.dump(self.issues, f)}
File.open("arguments.yml", "w") {|f| YAML.dump(self.arguments, f)}
FileUtils.rm "question.txt"
endNow, since we don’t know how the printer is going to react when we have long lines, let’s make an enhancement and wrap the text for it. (Also, lpr is the command for me on Ubuntu. You may need to use some other shell command, like “print” in Windows.)
def take_questions
select_round
current_questions.each do |q|
File.open("question.txt", "w") {|f| f.write word_wrap(q, 75) } # wrap to 75 columns
system "lpr question.txt"
end
save_files
end
# Gratuitously lifted from ActionView::Helpers::TextHelper
def word_wrap(text, line_width = 80)
text.gsub(/\n/, "\n\n").gsub(/(.{1,#{line_width}})(\s+|$)/, "\\1\n").strip
endFinally, let’s put one line at the end of the file that prints the questions automatically.
QuestionSelector.new.take_questionsAwesome!